
FDA: via libera ad AIM-NASH, primo strumento AI per accelerare i farmaci contro le malattie del fegato
La Food and Drug Administration statunitense ha approvato AIM-NASH, il primo strumento di intelligenza artificiale pensato per supportare lo sviluppo di farmaci contro le patologie del fegato. Non è un assistente generico: è una piattaforma cloud che analizza le immagini delle biopsie epatiche per identificare grasso, infiammazione e cicatrici, con risultati che l’agenzia giudica comparabili alle valutazioni effettuate da singoli esperti. L’obiettivo è chiaro: standardizzare le letture istologiche e ridurre tempi e risorse nei trial, soprattutto sulla steatoepatite associata a disfunzione metabolica (MASH), che interessa milioni di persone.
Cosa significa davvero questa approvazione
Dal punto di vista clinico, il valore è nella coerenza: la lettura di una biopsia dipende dall’esperienza del patologo e dall’interpretazione. Un sistema come AIM-NASH promette di rendere ripetibili e misurabili criteri che oggi soffrono di variabilità. Per i team che disegnano trial, questo si traduce in endpoint più stabili e in un arruolamento potenzialmente più rapido. Secondo la FDA, lo strumento potrà essere usato in qualsiasi programma di sviluppo di farmaci, con benefici diretti per gli studi su MASH.
Dal punto di vista tecnico, parlare di “AI” qui significa orchestrare un flusso robusto: ingestione sicura delle immagini istologiche, inferenza su cloud, tracciabilità completa dei risultati e un anello di validazione umana. È un pattern che chi lavora con piattaforme data-centric riconosce e può replicare in altri contesti medici.
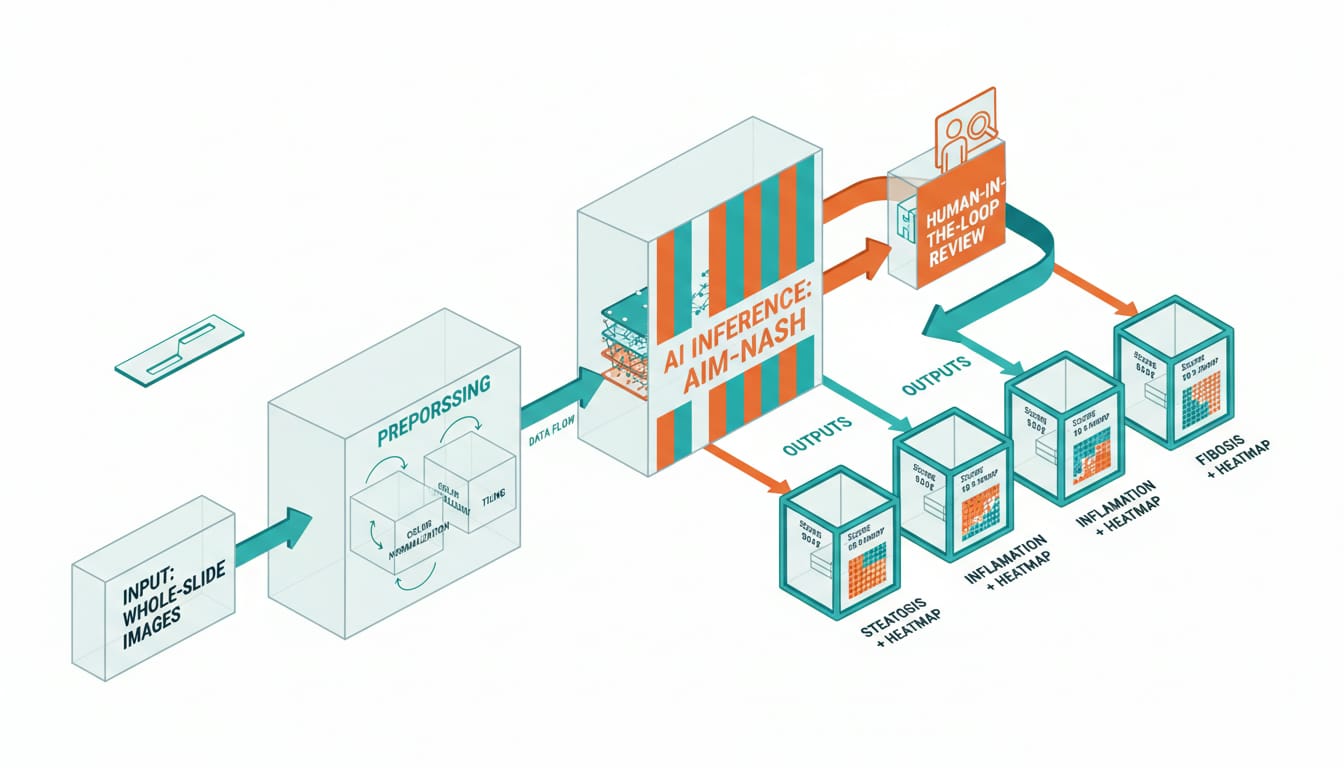
Dalla lastra al dato utile: una pipeline tipo
In pratica, la pipeline minima per un contesto regolato ruota attorno a pochi passaggi ben definiti. Non servono fuochi d’artificio, ma disciplina ingegneristica: versioning dei modelli, audit trail, e un chiaro “chi ha deciso cosa e quando”.
# Pseudo-pipeline per valutazioni istologiche standardizzate
pipeline:
ingest:
source: liver_biopsy_images
metadata: patient_id_hash, site_id, stain_protocol
preprocess:
steps: color_normalization, tile_generation
inference:
model: AIM_NASH
outputs: steatosis_score, inflammation_score, fibrosis_score
review:
human_in_the_loop: pathologist_signoff
compare: pathologist_grade_vs_ai
persistence:
store: immutable_object_storage
log: model_version, thresholds, operator_id, timestamp
reporting:
export: trial_EDC_endpoints
Questo approccio aiuta a chiudere il cerchio tra laboratorio e operations. Anche senza entrare nei dettagli implementativi, è il modo più diretto per passare dalla ricerca alla pratica clinica in contesti distribuiti (più centri, regole diverse, qualità d’immagine variabile).
L’impatto sui trial MASH: meno attrito, più segnale
I trial sulla MASH hanno un problema storico: endpoint istologici complessi e variabilità tra lettori. AIM-NASH, stando a quanto indicato dall’agenzia, può semplificare le sperimentazioni cliniche e uniformare le valutazioni. Questo si traduce in un time-to-signal più rapido: identificare prima se un candidato farmaco sta andando nella direzione giusta significa risparmiare cicli di iterazione e, in prospettiva, ridurre i costi di sviluppo.
Standardizzare la misura non è un dettaglio tecnico: è la differenza tra un trial che naviga a vista e uno che legge strumenti affidabili.
Per i team engineering e data, il lavoro vero è sui bordi del sistema: normalizzare le differenze di colorazione, controllare il drift tra centri clinici, definire soglie e protocolli di rianalisi quando l’AI e il patologo non concordano. La qualità non nasce nel modello, ma nel processo.
Trade-off tecnici da tenere d’occhio
- Dataset shift tra siti: piccoli cambi nei protocolli di colorazione possono spostare le distribuzioni. Serve monitoraggio continuo e ricalibrazione controllata.
- Interpretabilità sufficiente allo scopo: mappe di attenzione e report strutturati aiutano il confronto con il patologo senza scadere nel black-box totale.
- Gestione del disaccordo: definire in anticipo quando scatta il secondo parere umano e come rientra nel dato finale dell’end-point.
- Governance del ciclo di vita: versioni di modello e di soglie devono viaggiare insieme ai dataset e ai report, altrimenti la riproducibilità svanisce.
Cosa possiamo portare a casa, subito
Se dovessi impostare un progetto analogo, partirei così: restringere il perimetro (una sola metrica istologica ben definita), investire in un set di verità a terra con più lettori indipendenti, mettere in piedi una pipeline cloud con controlli di qualità automatici e una review umana strutturata. Poi iterazioni corte, convalida su siti diversi e reportistica pensata per chi conduce il trial, non per gli sviluppatori.
Con l’approvazione di AIM-NASH, il messaggio è semplice: l’AI può diventare infrastruttura affidabile per la ricerca clinica, non un orpello. E quando la misura è stabile, tutto il resto — dalla decisione di proseguire a quella di fermarsi — diventa più onesto e più veloce.