
Il modello di ragionamento gerarchico che sfida i limiti delle LLM
Negli ultimi anni abbiamo assistito a un’esplosione delle capacità delle Large Language Model (LLM).
Le abbiamo viste scrivere testi complessi, ragionare in modo sorprendente e addirittura generare codice funzionante. Ma sotto la superficie di questo entusiasmo, c’è una verità un po’ scomoda: le architetture alla base delle LLM non sono nate per ragionare in senso stretto. Sono, in fondo, macchine predittive di sequenze di token. Bravissime a completare frasi, meno eccellenti quando si tratta di pianificare a lungo termine, di fare backtracking o di eseguire ragionamenti profondamente annidati.
Chi ha provato a spingere le LLM su terreni come i Sudoku estremi o la navigazione ottimale in un labirinto di 30x30 celle lo sa bene: il classico approccio “Chain-of-Thought” (CoT) – in cui il modello esternalizza il ragionamento scrivendolo passo passo – ha limiti strutturali. È lento, fragile e dipende molto dalla bontà della decomposizione in step fatta a monte.
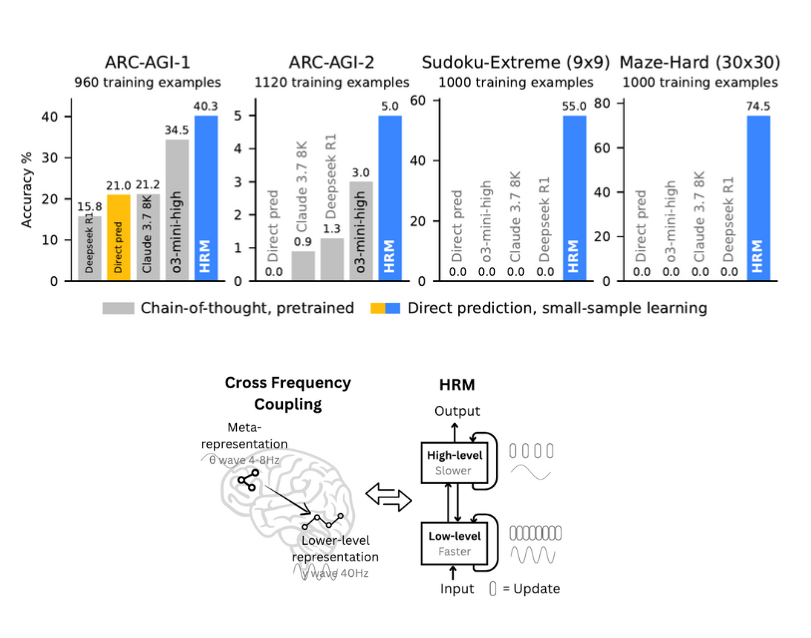
Ed è qui che entra in gioco HRM, Hierarchical Reasoning Model, una nuova architettura che prende ispirazione direttamente dal cervello umano e dal modo in cui gestisce il ragionamento su più livelli e a diverse velocità. Il bello? HRM non ha bisogno di pre-addestramento titanico, né di catene di pensiero esplicite. Con appena 27 milioni di parametri e un migliaio di esempi per task, è riuscito a risolvere problemi che mettono in crisi modelli molto più grandi e blasonati.
Quello che voglio fare in questo articolo non è solo raccontarti i numeri, ma portarti dentro la logica e la filosofia che stanno dietro HRM, con un occhio critico ma anche un po’ entusiasta (perché, ammettiamolo, un modello così piccolo che umilia giganti è sempre una storia bella da raccontare).
Il problema di fondo: profondità effettiva e ragionamento
Il deep learning, ironia della sorte, non è sempre così “deep” come vorrebbe far credere il nome. I Transformer, cuore pulsante delle LLM, hanno una profondità fissa e relativamente modesta. Questa profondità è sufficiente per un certo tipo di pattern matching e inferenza statistica, ma si scontra con un muro quando bisogna eseguire algoritmi che richiedono calcoli iterativi e profondi, come la ricerca in alberi complessi o la manipolazione simbolica avanzata.
Dal punto di vista della complessità computazionale, i Transformer standard stanno in classi come AC⁰ o TC⁰. Tradotto: non sono Turing-completi e non possono, in modo end-to-end, risolvere certi problemi che richiedono tempo polinomiale. È per questo che la comunità ha cercato “stampelle” come il Chain-of-Thought, che trasforma il ragionamento interno in linguaggio naturale, un po’ come se il modello pensasse ad alta voce.
Il problema? Pensare ad alta voce è inefficiente. È come se, per risolvere un Sudoku, ogni mossa dovessi scriverla, leggerla, capirla e poi fare la prossima. Bello per la trasparenza, pessimo per la velocità. Inoltre, se uno step è sbagliato, tutta la catena crolla.
HRM affronta la questione in modo radicalmente diverso: invece di appoggiarsi al linguaggio come supporto del ragionamento, sposta il grosso del lavoro in uno spazio latente, più vicino al “pensiero interno” che non alla narrazione esplicita. E qui entra in gioco l’analogia con il cervello.
L’ispirazione biologica: cervello, gerarchie e tempi diversi
Il nostro cervello è un capolavoro di efficienza. Non processa tutto allo stesso ritmo e allo stesso livello di astrazione. Ci sono aree corticali che ragionano su scale temporali lunghe, accumulando e integrando informazioni, e altre che lavorano in modo rapido e dettagliato su stimoli immediati.
Questa architettura gerarchica e multi-temporale ha tre pilastri:
- Gerarchia di elaborazione: aree alte per il pensiero astratto, aree basse per il dettaglio operativo.
- Separazione temporale: ritmi lenti (theta) per il controllo globale, ritmi veloci (gamma) per l’esecuzione rapida.
- Connessioni ricorrenti: loop di feedback che raffinano continuamente le rappresentazioni.
HRM prende questa struttura e la traduce in due moduli ricorrenti interconnessi:
- un High-level module (H) che pianifica e aggiorna lentamente;
- un Low-level module (L) che esegue calcoli rapidi e dettagliati, più volte per ogni aggiornamento dell’H.
Questo schema evita il problema della “convergenza precoce” che affligge molte RNN, in cui lo stato interno smette di evolvere dopo pochi step, limitando la profondità effettiva del ragionamento.

Architettura e dinamica di HRM
A livello operativo, un input passa attraverso quattro componenti principali:
- Input network (fI) – proietta i dati in uno spazio di lavoro.
- Low-level recurrent module (fL) – aggiorna rapidamente lo stato, guidato dal contesto fornito da H.
- High-level recurrent module (fH) – si aggiorna solo alla fine di un ciclo L, riorientando il contesto globale.
- Output network (fO) – genera la predizione finale dopo un certo numero di cicli.
Il trucco è che per ogni ciclo ad alto livello (H), il modulo L fa T passi di calcolo interno, raggiunge un equilibrio locale, poi “passa la palla” ad H. H aggiorna la strategia, resetta L e il processo riparte. Così, con N cicli e T passi per ciclo, si ottiene una profondità effettiva di N × T, senza il peso computazionale e di memoria del Backpropagation Through Time (BPTT) classico.
Test e risultati: David contro Golia
Ecco dove HRM ha brillato davvero.
- ARC-AGI: benchmark di ragionamento induttivo. HRM (27M parametri) ha ottenuto il 40,3% superando o3-mini-high (34,5%) e Claude 3.7 8K (21,2%).
- Sudoku-Extreme (9x9): con 1000 esempi di training, HRM ha sfiorato la perfezione. Modelli CoT, anche molto grandi, hanno fatto 0%.
- Maze-Hard (30x30): HRM ha trovato percorsi ottimali dove i rivali non si sono mossi dalla partenza.
La parte più impressionante è la data efficiency: niente pretraining, niente CoT supervision, solo training diretto con input-output.
Come ragiona HRM (interpretabilità e strategie emergenti)
Analizzando gli stati intermedi, emergono pattern diversi a seconda del compito:
- Nei labirinti, esplora molteplici percorsi in parallelo, poi elimina quelli bloccati, affinando la soluzione.
- Nei Sudoku, adotta uno stile simile alla ricerca in profondità, con backtracking frequente.
- Nei task ARC, segue un miglioramento incrementale coerente, più vicino a un’ottimizzazione locale che a un backtracking.
Questo dimostra che HRM non applica un’unica strategia, ma adatta lo stile di ragionamento al problema.
Neuroscienza e corrispondenze con il cervello
Uno degli aspetti più affascinanti è che HRM, dopo l’addestramento, mostra un gradiente di dimensionalità tra H e L simile a quello osservato nella corteccia di un topo:
- H-module: alta dimensionalità (PR ≈ 89,95) → più flessibilità cognitiva.
- L-module: dimensionalità più bassa (PR ≈ 30,22) → più specializzazione.
Questa separazione non esiste in un HRM non allenato, il che suggerisce che emerga come proprietà dell’apprendimento, non come vincolo architetturale.
Riflessioni personali
Quello che mi colpisce di HRM è che non è solo un miglioramento tecnico, ma un cambio di mentalità. Stiamo passando da modelli che simulano il ragionamento raccontandolo (CoT) a modelli che lo vivono internamente, in silenzio, come facciamo noi.
E il fatto che un’architettura così compatta possa affrontare compiti proibitivi per giganti da miliardi di parametri apre scenari interessanti anche per l’edge computing e i sistemi embedded.
Uno sguardo al futuro
Non so se HRM diventerà lo standard, ma è una dimostrazione forte che l’ispirazione biologica può portare a soluzioni eleganti ed efficienti.
E mi lascia con una domanda aperta: cosa succederebbe se unissimo HRM a un backbone multimodale e lo lasciassimo imparare su un insieme ampio e variegato di compiti?
Potremmo forse avere un primo vero assaggio di ragionamento universale in AI.